Introduction
- The Argyle API is built on RESTful principles.
- The API operates over HTTPS to ensure the security of data being transferred.
- All requests and responses are sent in JSON.
- Visit our API Reference to learn more about each endpoint, and see example requests and responses.
- Subscribe to our Changelog to receive updates on changes to the API.
Implementations should accommodate additional fields and response values being added to existing endpoints as we continuously expand our data granularity.
Creating API keys
Production and Sandbox API keys can be created in Console.API key secrets are only visible during API key creation and partially obfuscated thereafter. Please ensure you copy and securely store API secrets when creating new API keys.
Authentication
All API requests are authenticated over standard HTTP basic authentication.- username —
api_key_id - password —
api_key_secret
Example
Protect your API keys from being revealed. See security for best practices.
Environments
Argyle provides two environments:
Both Link and the API can be used in either the Sandbox or Production environment.
The Sandbox environment lets you connect sample users in Link, and retrieve their sample data via the API. Visit our dedicated Sandbox Testing Guide for more information.
All API endpoints can be used in either the Sandbox or Production environment, with the exception of an additional Sandbox endpoint that lets you simulate data refreshes and update sample data.
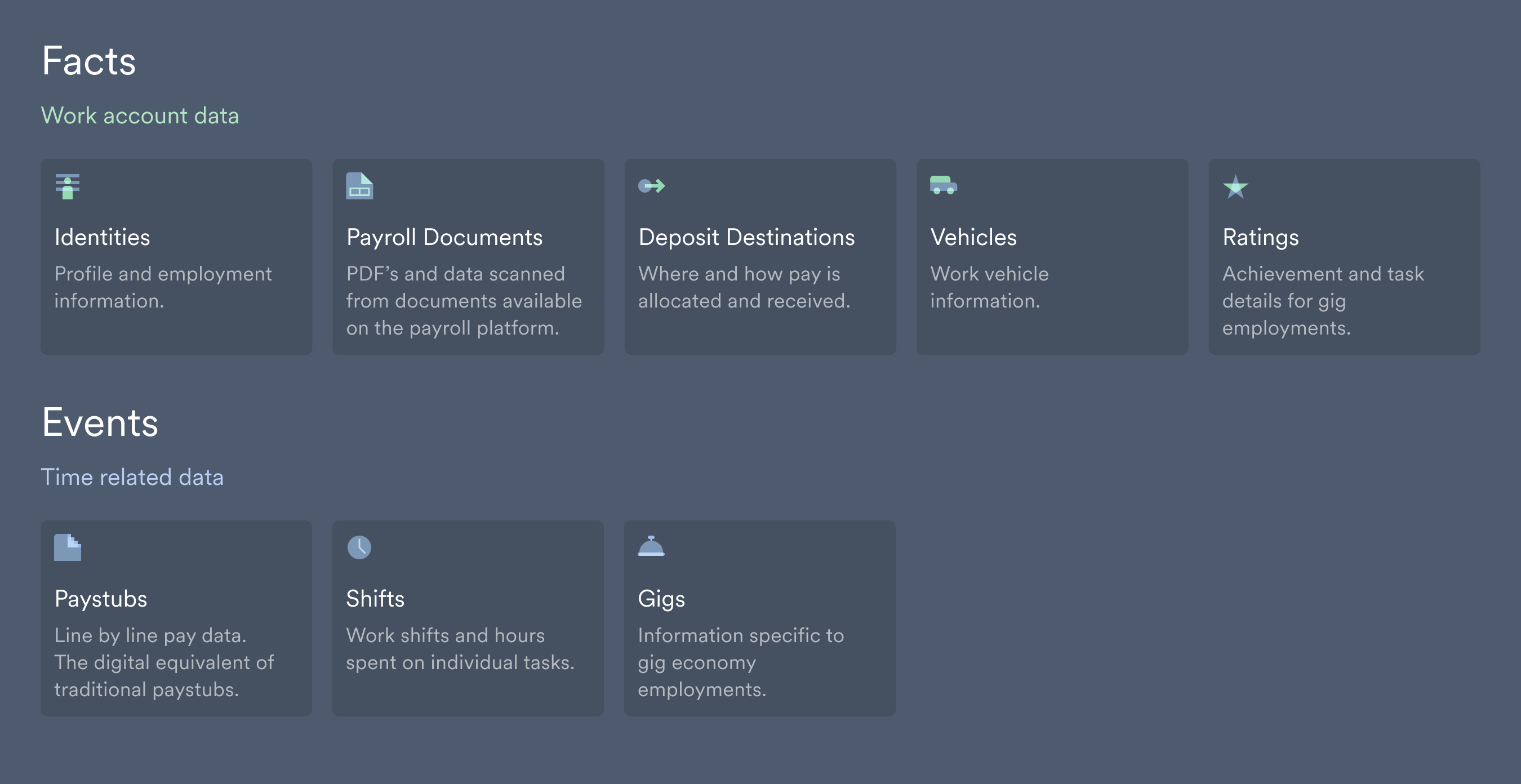
Data availability
Data is collected in stages after a new account is connected:Fact data
- Available soon after a payroll connection.
- Static information that tends to change less over time.
Event data
- Retrieved and made available from most recent to least recent.
- Time-dependent information that can go back a number of years.
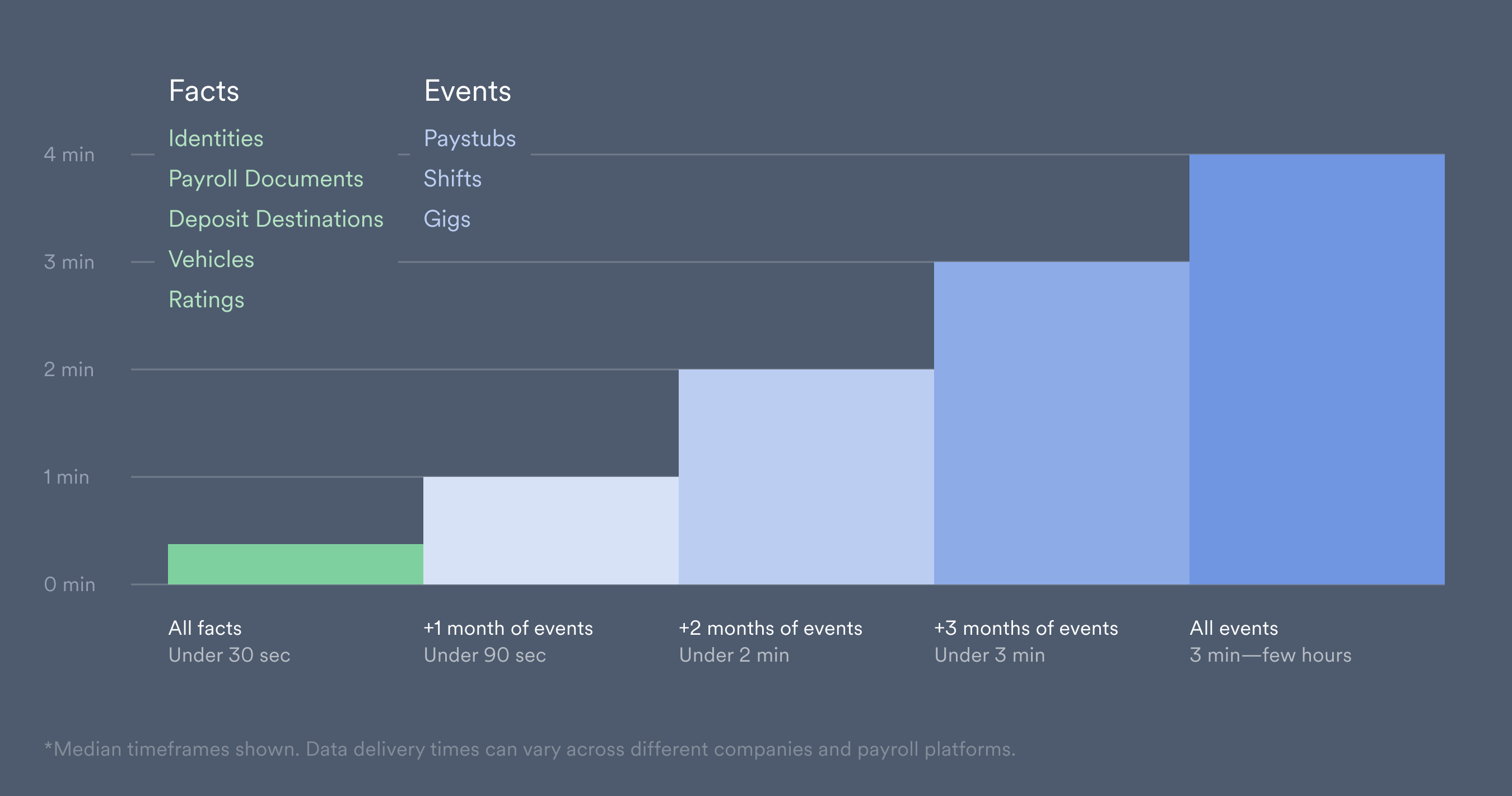
Visit our Data Delivery Guide for more information on data availability after a new account connection.
Breaking changes
Subscribe to our Changelog to receive updates on changes to the API.
- Changing authentication or authorization requirements
- Removing or re-naming an endpoint
- Removing or re-naming a webhook
- Removing or re-naming a required request parameter
- Adding a required request parameter (including previously optional parameters)
- Removing or re-naming any field name (including objects, arrays, or individual properties)
- Changing the type of any field, request parameter, or query parameter
- Adding an endpoint
- Adding a webhook
- Adding an optional request parameter
- Adding additional response fields (including objects, arrays, or individual properties)
- Returning new response field values
- Returning additional enum values, including new errors
- Changes to error messages
- Fixes to HTTP response codes from an incorrect code to a correct code
Security
Secure your API keys using these best practices:- Only invoke the Argyle API from your own server-side applications.
- Avoid including or adding checks for your API keys in client-side code.
- Store API keys in environment variables or files outside your application’s source tree, instead of embedding them directly in your application.
Storing API keys outside your application’s source tree is particularly important if you use a public source code management system such as Github.
- Use one set of API keys for each backend system on your platform. This limits the scope of compromised API keys.
- Delete unused API keys.
System status
Argyle publishes operational status by solution and channel on status.argyle.com. Incidents, updates, and related messaging are posted there and sent automatically to subscribers. GET requests made to the following URLs can also be used to retrieve status and incident information programmatically:Status codes
The Argyle API uses the following HTTP response codes:Error responses
When an error occurs, a JSON object is sent in the response describing the error.Example
Example
Null values
If all data fields are not available, Argyle will still return partial data records. Individual fields may returnnull values when:
- The data source does not support that field.
- The data source supports the field, but no information is present.
[].
Objects may return either an empty {} or object instance where all properties are set to null.
Example
Pagination
All “List” GET requests (“list paystubs”, “list identities”, etc.) return paginated results. The number of results per page can be defined by using thelimit parameter when making the request. The default number of results per page is 10, and the maximum is 200.
Paginated responses will have next and previous page URLs:
next field.
Following the next and previous page URLs helps avoid retrieving duplicate results and eliminates redundant calls. This ensures no two requests can happen in parallel to avoid 429 rate limiting responses.
See concurrency below if you are bulk fetching data using parallel requests.
Rate limiting
The API allows 50 requests per second. If this rate is exceeded, a429 status code will be returned.
Rate limiting may occur during periods of high request volume, often related to analytical or data migration operations.
We recommend including a retry method in your applications that responds to 429 status codes by scaling down your request volume and returning rate limited requests to your queue.